Code Agent Blog Reading
主要思路是feature和具体用了什么技术
Claude Code
RAG
https://www.anthropic.com/engineering/contextual-retrieval 小于20w个tokens,可以直接放入prompt中 超出上下文窗口的大型知识库,可以用RAG做预处理
- 知识库分解成更小的文本块,不超过几百个tokens
- Embedding mode 转换为向量嵌入,存储在数据库中,按语义相似性进行搜索 这种方法是根据语义相似度查询最相关的词块的 但可能会在一些精确匹配上发生错配 使用BM25,可以精确匹配术语
- TF-IDF(Term Frequency-Inverse Document Frequency)来衡量词对文档的重要性
- 对词频运用饱和函数,防止常用词主导结果
- 这样可以查找到一些精确的表述
标准RAG,用两种方法检测,最后用排序融合技术去重,排序
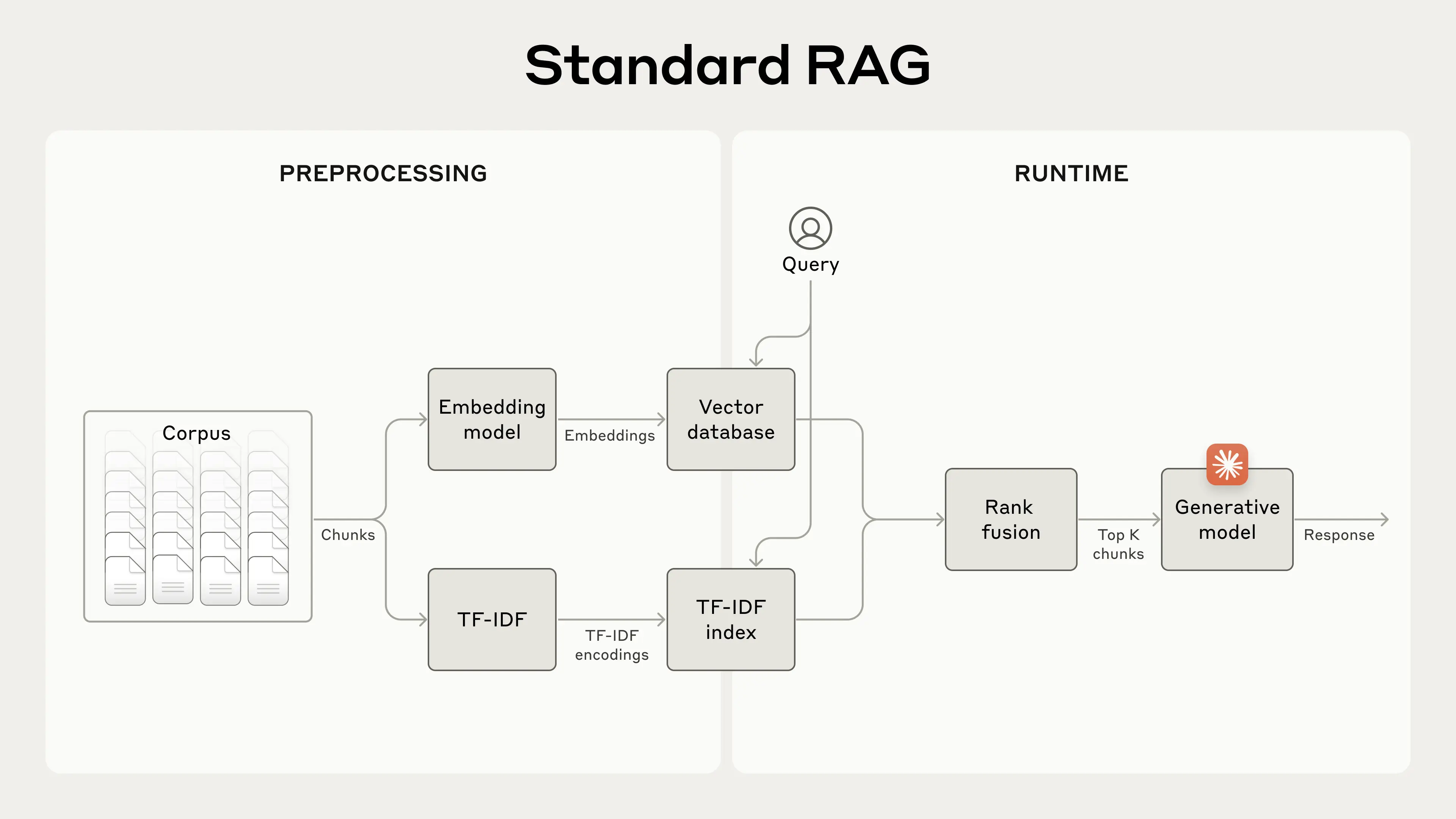 然而传统RAG缺乏一些上下文信息,这些信息也很难检索到
引入上下文检索(在embedding之前用LLM为每个块添加解释性上下文)
然而传统RAG缺乏一些上下文信息,这些信息也很难检索到
引入上下文检索(在embedding之前用LLM为每个块添加解释性上下文)
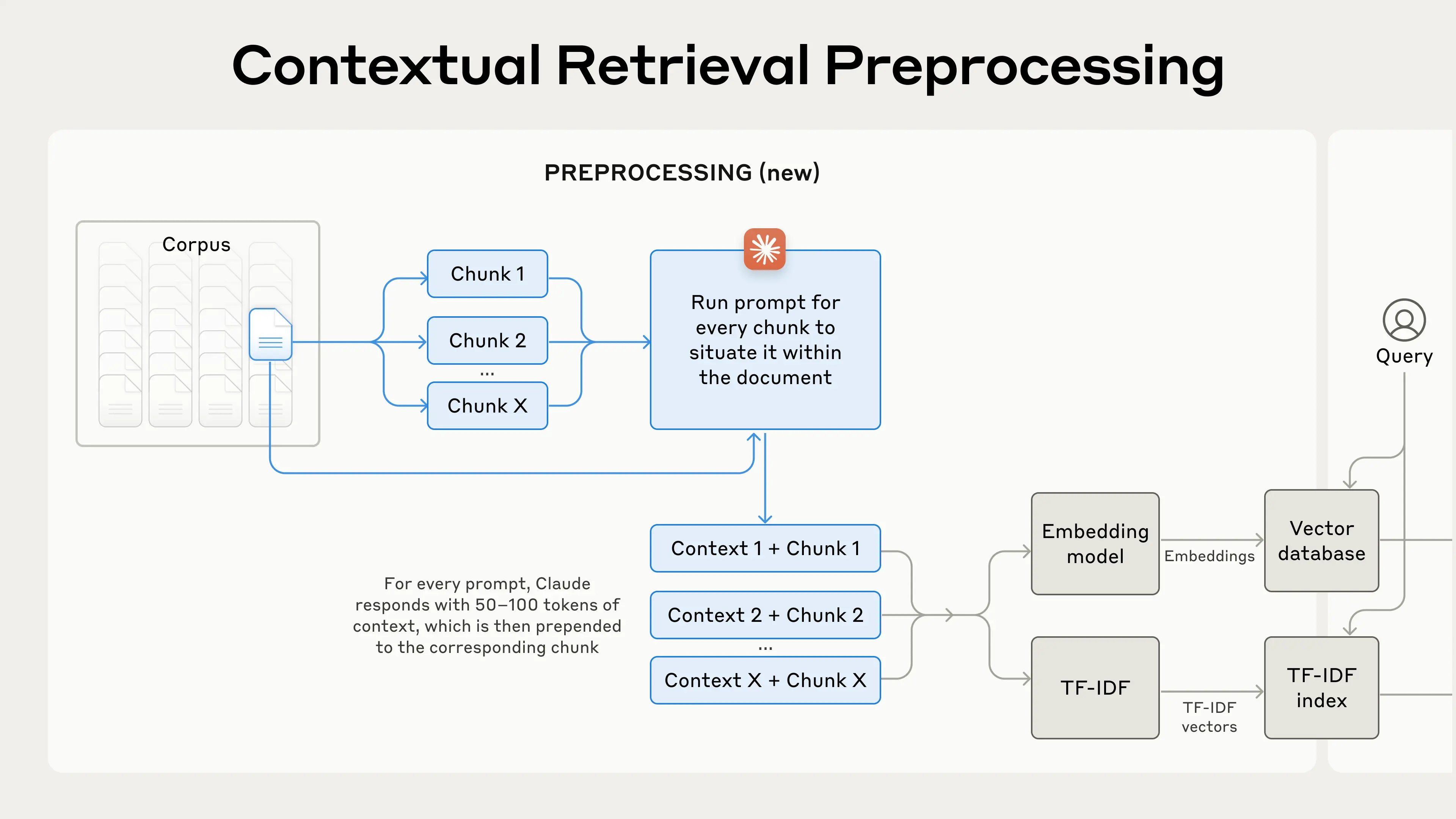 需要考虑数据块边界/嵌入模型/上下文提示(术语词汇表)/信息块数量
并区分哪部分是上下文哪部分是块
除此之外,用reranking可以进一步提升性能
需要考虑数据块边界/嵌入模型/上下文提示(术语词汇表)/信息块数量
并区分哪部分是上下文哪部分是块
除此之外,用reranking可以进一步提升性能
Effective agents
workflow&agents
workflow:通过预定义的代码路径协调LLM和工具(可预测与一致性)
agents:LLM动态知道自身流程和工具使用,从而保持对完成任务方式的控制(大规模灵活性和模型驱动)
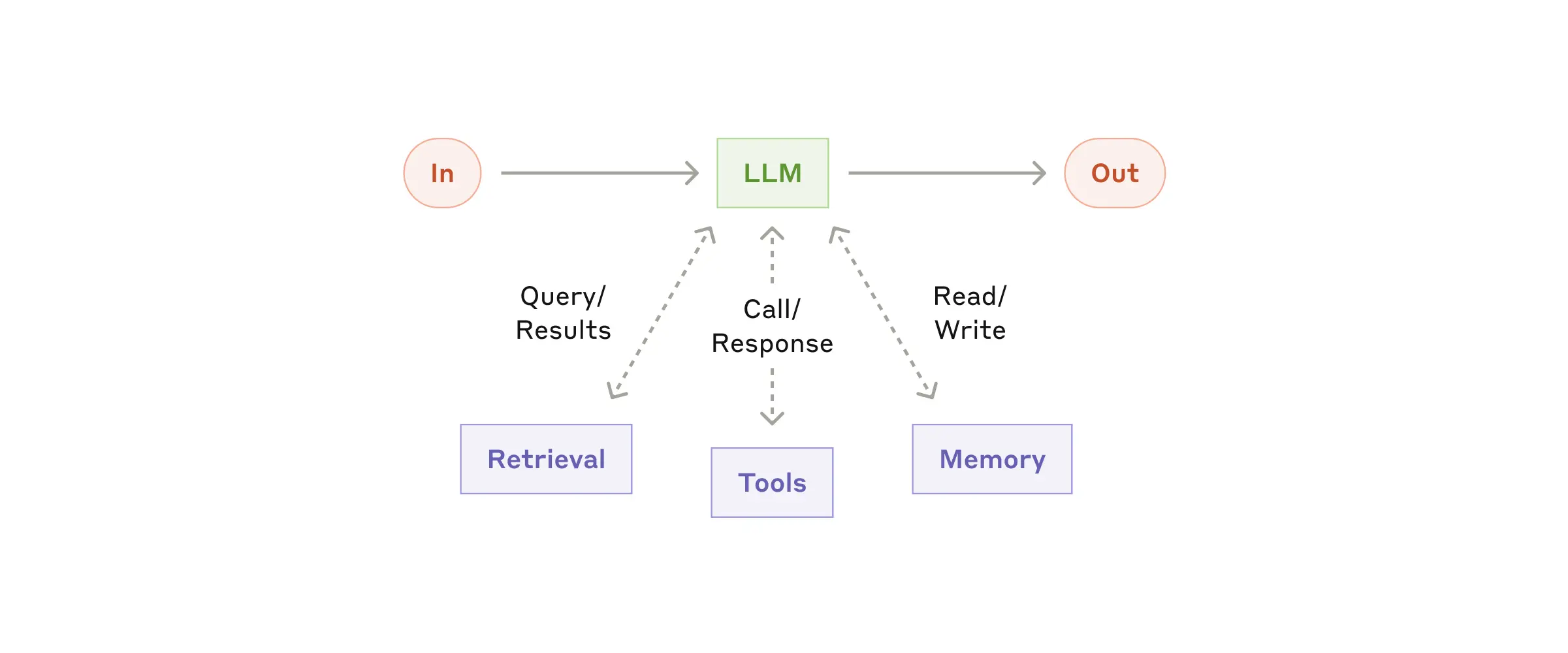
augmented LLM
 Prompt chaining: 用于易于分解为子任务的情况,牺牲延迟换准确率
Prompt chaining: 用于易于分解为子任务的情况,牺牲延迟换准确率
 Routing: 输入分离,导向特定任务,从而构建更具有针对性的提示,适用于复杂任务(可以实现用LLM/分类模型进行分类)
Routing: 输入分离,导向特定任务,从而构建更具有针对性的提示,适用于复杂任务(可以实现用LLM/分类模型进行分类)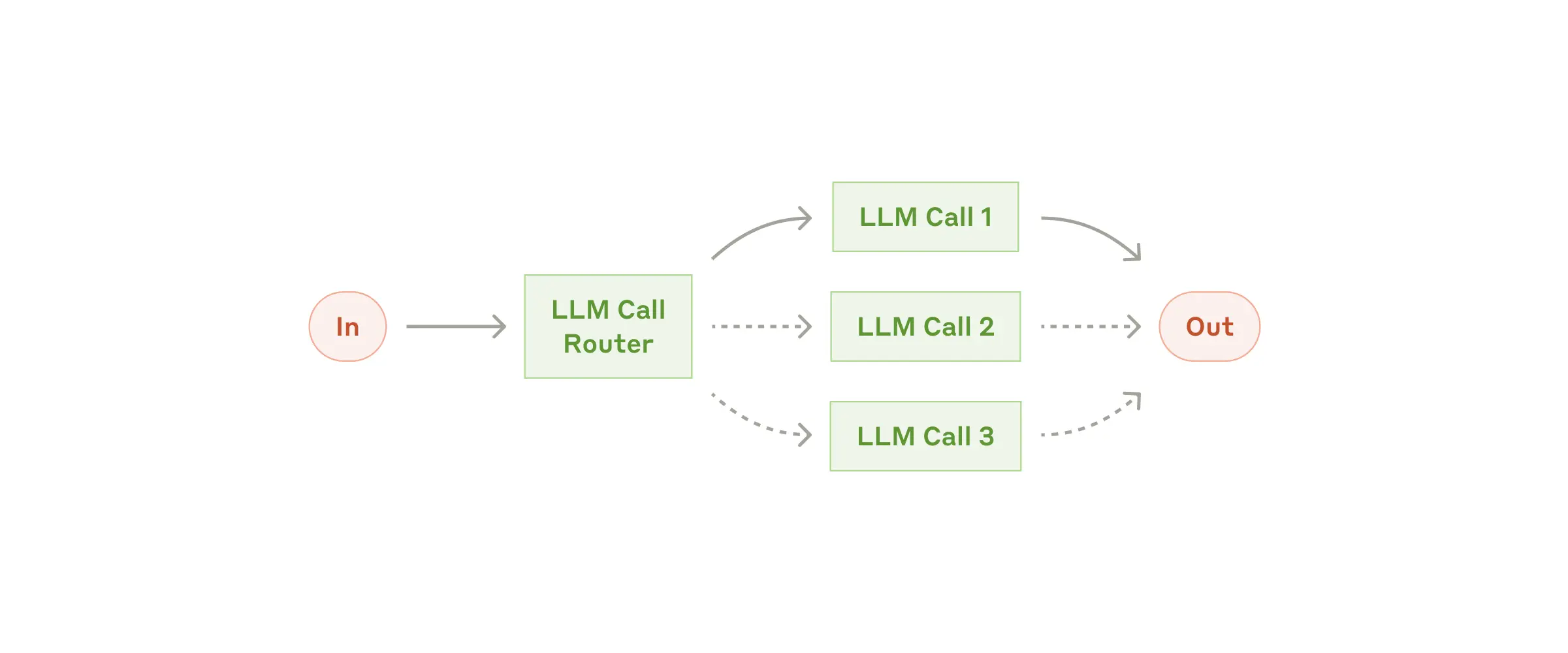 并行化:分解为可以独立运行的子任务(提高速度)/多次运行同一任务获得输出结果(获得更高置信度的结果)
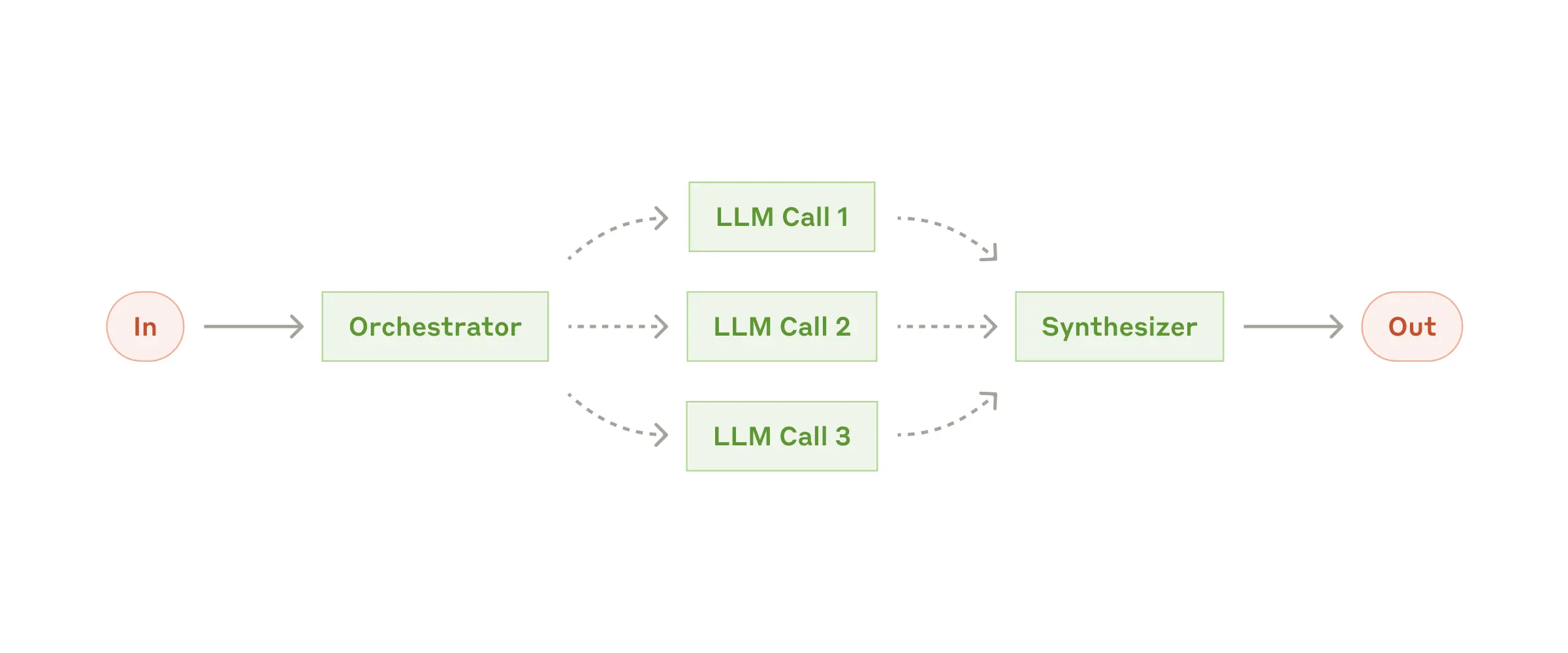
并行化:分解为可以独立运行的子任务(提高速度)/多次运行同一任务获得输出结果(获得更高置信度的结果)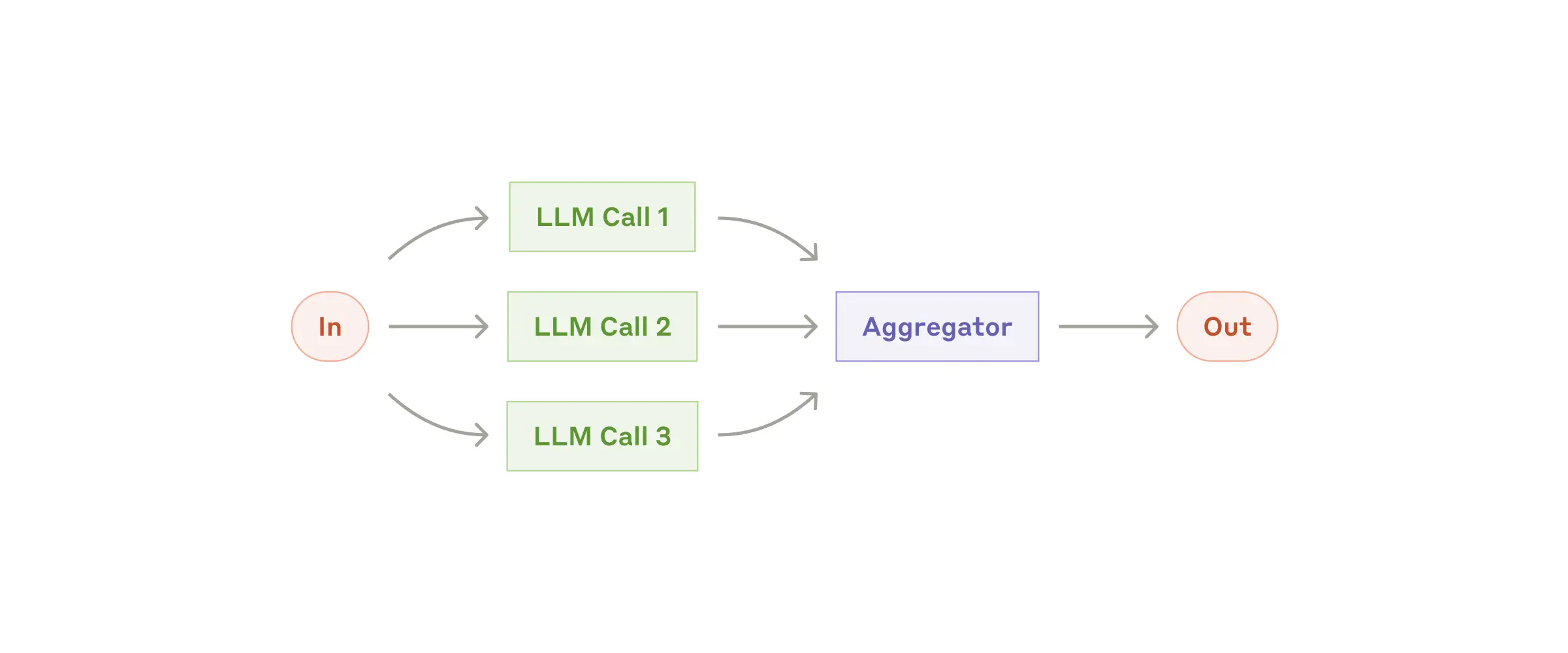 Orchestrator-workers:中央LLM动态分解任务给一些LLM,后者综合它们的结果,用于难以预测所需子任务的复杂任务,这些子任务由具体输入确定(更灵活)
Orchestrator-workers:中央LLM动态分解任务给一些LLM,后者综合它们的结果,用于难以预测所需子任务的复杂任务,这些子任务由具体输入确定(更灵活)
 Evaluator-optimizer:评估标准明确,且迭代改进能带来可衡量的价值
Evaluator-optimizer:评估标准明确,且迭代改进能带来可衡量的价值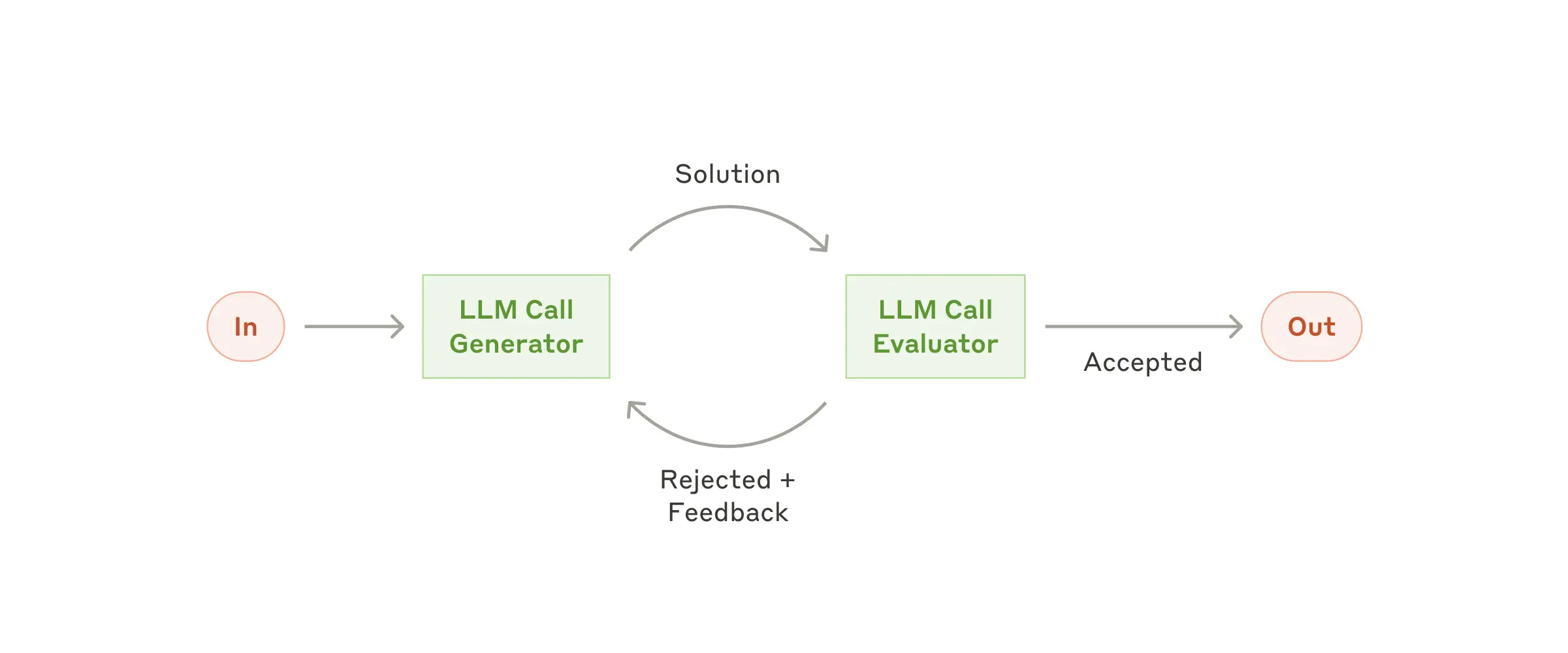 agent:在可行环境中扩展任务
agent:在可行环境中扩展任务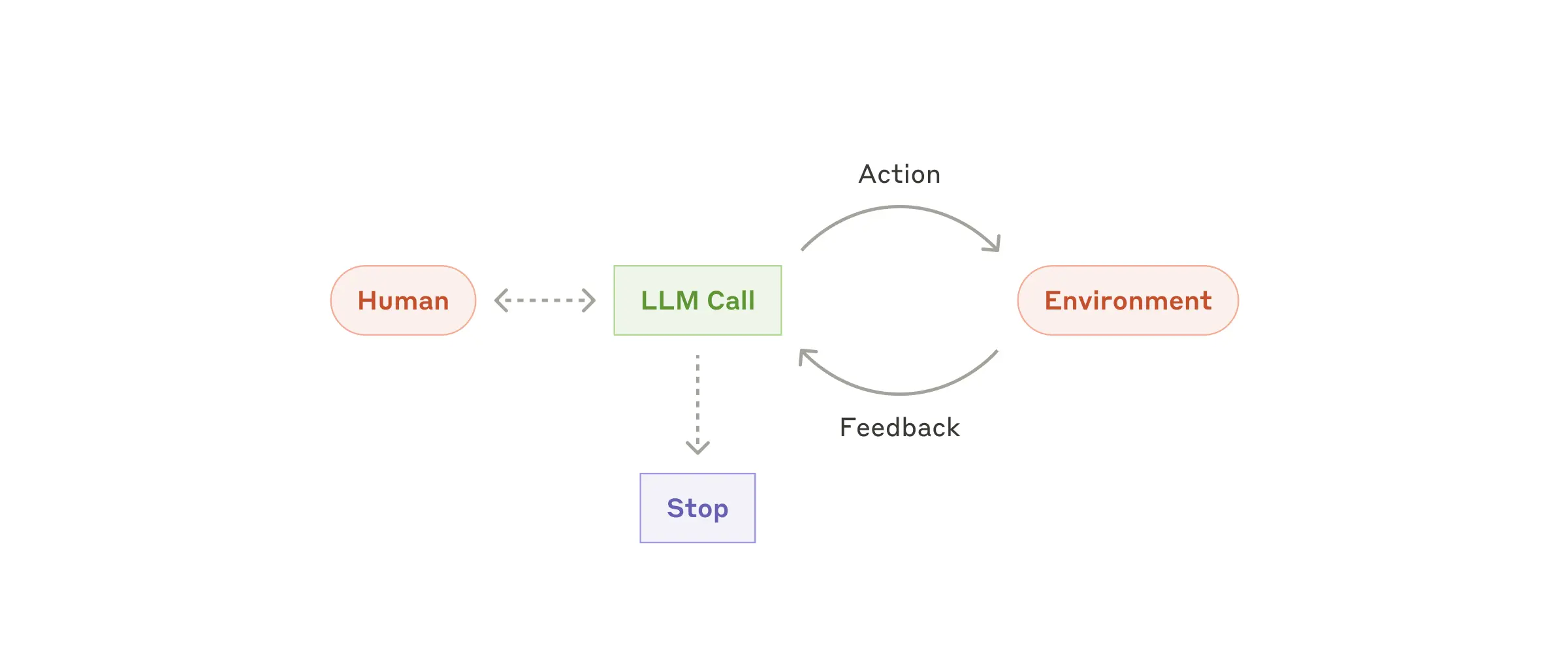
- 在选择工具格式时,工具的描述或许比模型本身更重要,
- 给模型足够的思考空间,在陷入困境前先让它思考
- 保证格式接近互联网上自然出现的文本格式
- 确保没有格式“开销”
Multi-agent System
https://www.anthropic.com/engineering/multi-agent-research-system
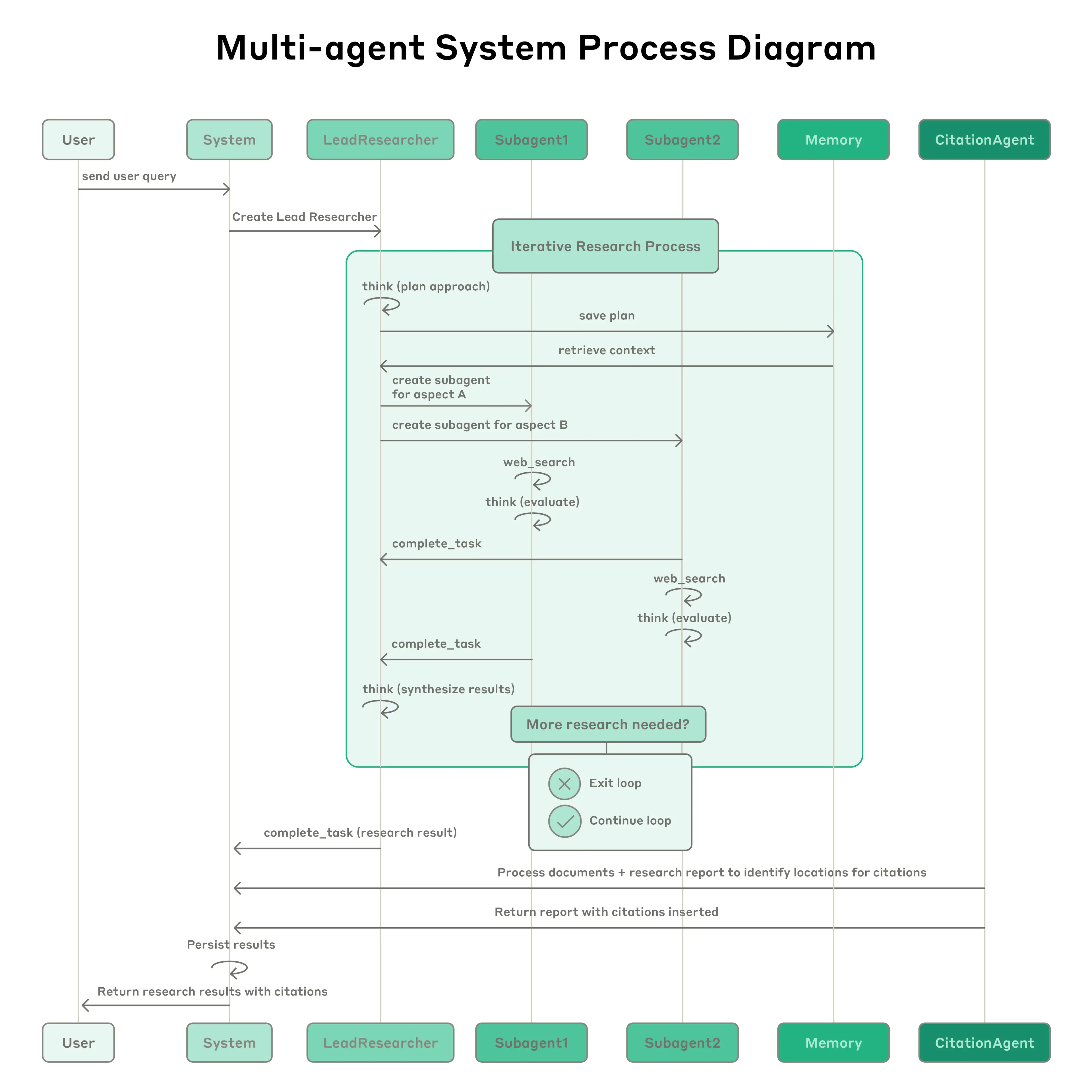
- 评估:小样本/LLM(二分类最好)/人类
- 一些有趣的点
- 错误发生时让智能体恢复运行
- 进行跟踪
- 部署需要协调
- 同步执行造成瓶颈(主代理无法控制子代理,子代理之间无法协调),用异步执行,实现更高的并行性(但带来结果协调,状态一致性以及错误的挑战)
Context Engineering
https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
主要是针对context engineering
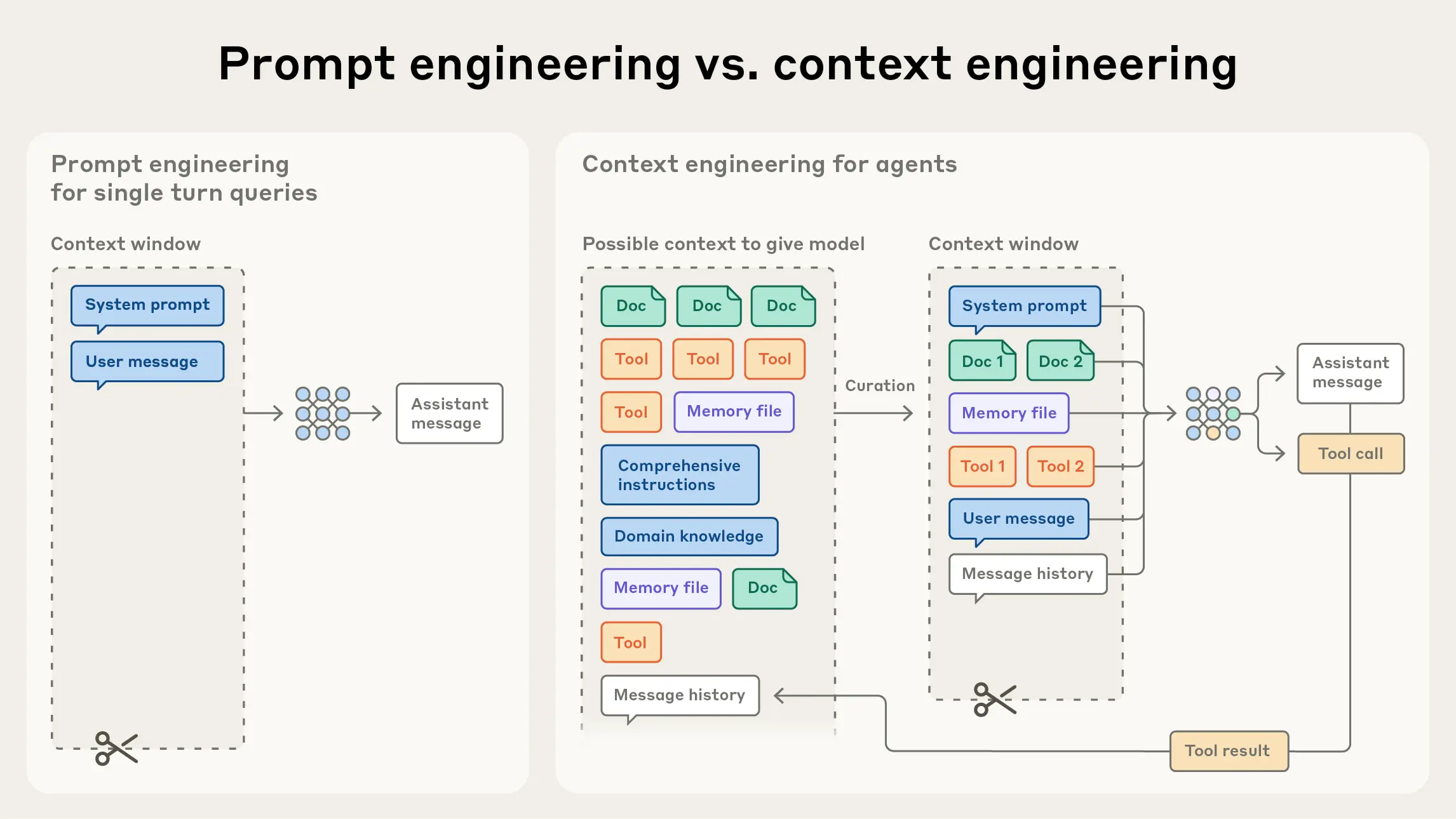 问题:上下文腐烂,上下文token越多,llm就越注意不到特定词元(n个词元配 个成对关系),上下文越大,注意力就越集中不了
好的上下文工程:找到尽可能小的高信号词元集合,最大化预期结果的概率
从上下文搜索(将一些信息attach到prompt之中)到“即时”搜索,通过工具动态将数据加载到上下文中(渐进式披露,claude还有一篇blog讲了它们的Agent skill参考 ,这个相当于是为Agent弄了一个循序渐进的知识库)(Claude Code)
问题:上下文腐烂,上下文token越多,llm就越注意不到特定词元(n个词元配 个成对关系),上下文越大,注意力就越集中不了
好的上下文工程:找到尽可能小的高信号词元集合,最大化预期结果的概率
从上下文搜索(将一些信息attach到prompt之中)到“即时”搜索,通过工具动态将数据加载到上下文中(渐进式披露,claude还有一篇blog讲了它们的Agent skill参考 ,这个相当于是为Agent弄了一个循序渐进的知识库)(Claude Code)
- 自动搜索/检索数据可以让模型通过探索逐步发现相关上下文(但比预先检索更慢,还需要对工具的把握)
- 混合检索(比如事先把
CLAUDE.md放到上下文中,工具则进行实时检索) 而关于长周期任务,agent需要在一系列动作中保持连贯性,上下文关联性和目标导向行为,需要一些技术来克服上下文窗口的限制 - 压缩(对话流畅性):将接近上下文窗口上限的对话进行内容概括,之后重新创建新的上下文窗口(保留架构决策,没有解决的错误和实现细节,丢弃冗余 的工具输出和消息,并用这个上下文和最近访问的五个文件执行任务)
- 需要最大化召回率,保证所有信息都被捕捉到,之后迭代优化去除冗余内容,比如清除工具调用和结果
- 结构化笔记/agent memory(设定明确里程碑的迭代开发)
- 让智能体定期记录笔记,并存储在上下文窗口之外的记忆之中,可以跟踪复杂任务的进度,保留关键的上下文和依赖关系
- 这使得智能体能够随着时间的推移构建知识库,跨会话维护项目状态,并在无需将所有内容都保留在上下文中的情况下引用之前的工作。
- (游戏攻略?
- 子代理架构(处理复杂的研究和分析,并行探索 )
- 让主代理负责协调高层策划,子代理执行深入的工作或者用工具查看相关信息
- 职责分离
Eval(对agent进行评估)
Demystifying evals for AI agents \ Anthropic
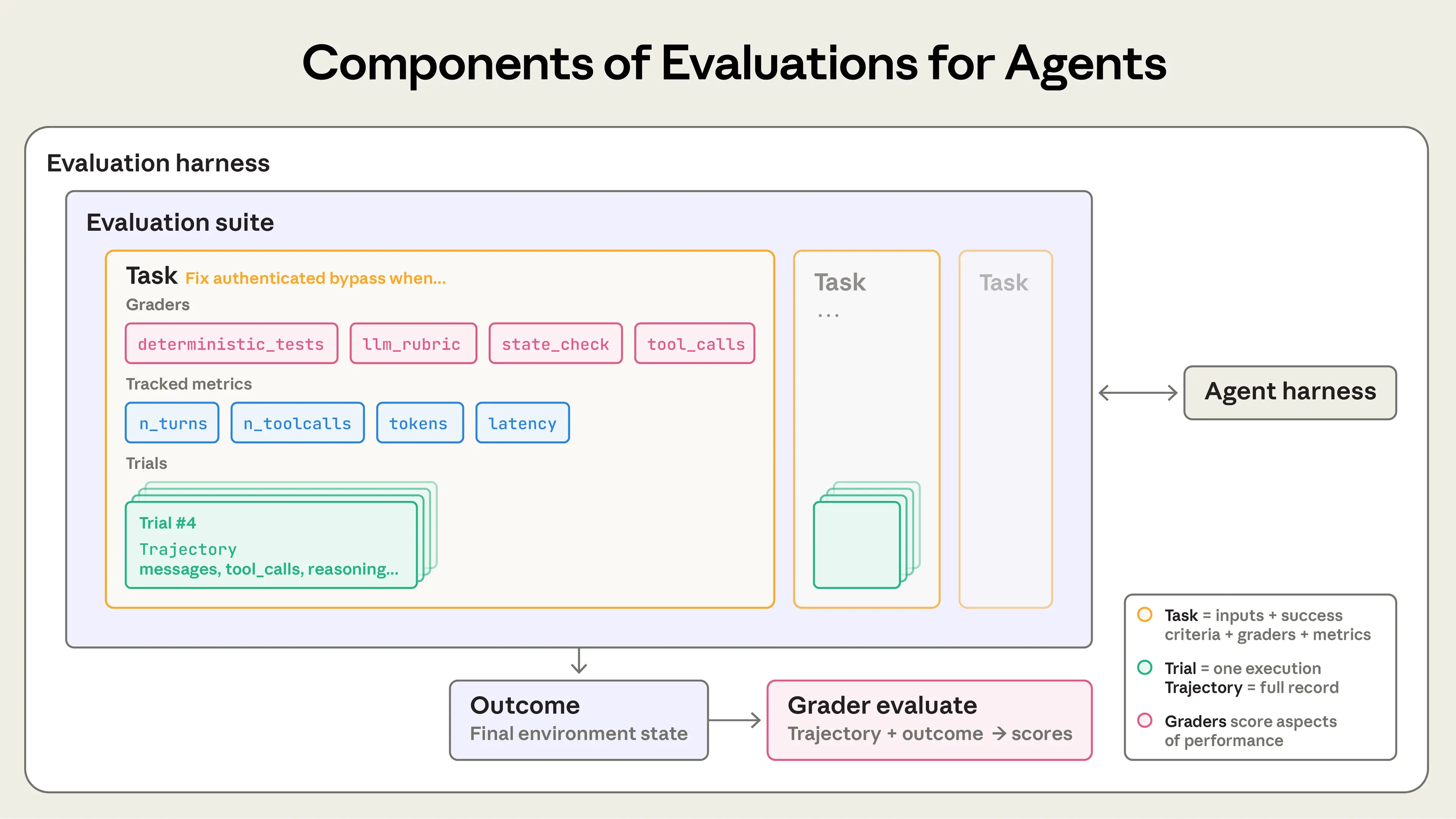
- 评估的结构
- 单回合(提示,回应和评分逻辑)
- 多回合(使用工具,改变环境状态并评估工具的结果)
评估的具体构成如下图
- 评估的方法
- 基于代码(做字符串匹配,测试,静态分析,是否找到正确的结果,是否调用正确的工具,运行了几轮,烧了多少token)
- 快速方便,易于调试
- 评估主观任务受限
- 基于模型(评分,比较,多个agent达成共识)
- 灵活,有可扩展性,处理自由格式输出
- 不确定,贵,需要用人工保证准确性
- 人工(特定领域的专家评测,人群检测,抽查抽样,AB测试)
- 最好的标准
- 很贵,慢,需要接触到专家
- 基于代码(做字符串匹配,测试,静态分析,是否找到正确的结果,是否调用正确的工具,运行了几轮,烧了多少token)
- 评估的时候应该评估agent可以完成它以前能完成的任务,并且通过率100%
- 对coding agent的评估:代码运行/测试是否通过
- 对话agent的评估:是否解决问题/是否在给定的回合内完成任务,语气是否合适(需要另�一个模型扮演用户)
- search agent评估:验证引用来源是否包含agent声称具有的内容,同时验证一个预期的答案包含的关键事实,且来源具有权威性。对答案本身是客观的任务可以进行精确匹配
- 计算机使用agent:评估agent使用软件的状态,以及它是否达到最终效果,检查任务完成之后的各种产物。如果是针对浏览器的代理,则需要在消耗token的数量和延迟之间取得平衡(是直接从dom种提取文本还是截图)
然而,agent评测的结果具有非确定性,因此要用一些统计性的指标来进行评估
- pass@k:agent在k次尝试种至少得到一个正确解的可能性
- pass^k:k次实验成果的概率
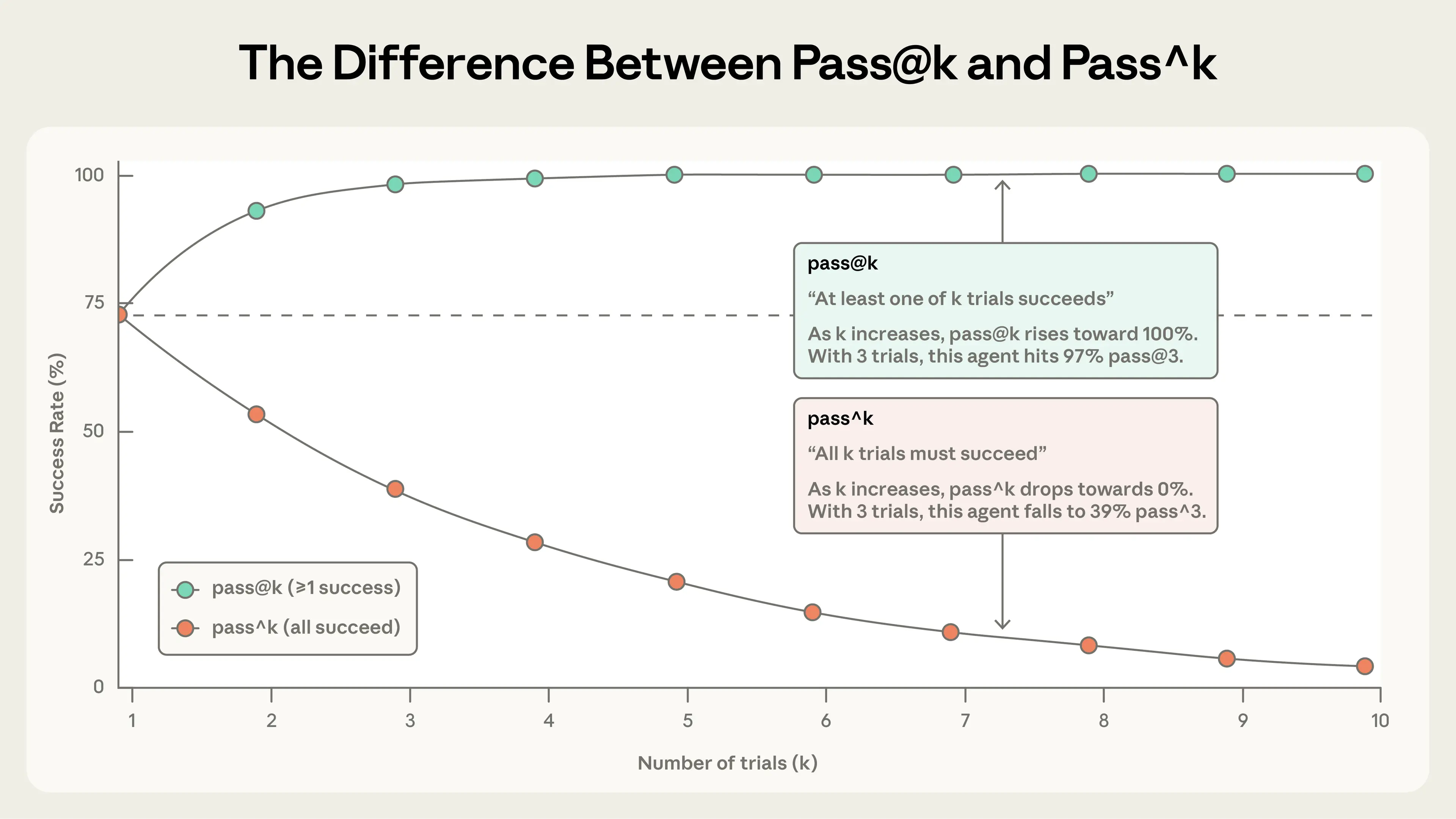 一些在构建过程中的insight
一些在构建过程中的insight
- 测试行为包括该发生和不该发生的情况,在这两种情况之间进行tradeoff
- 评估环境和生产环境应当保持一致
- 对agent产出的内容而非轨迹进行评测,否则会过于死板
系统的评估应该与其他评估的方法配合
- 自动化评估
- 生产中监控
- A/B测试
- 用户反馈
- 人工审核
- 系统性的人类研究
Skills
Equipping agents for the real world with Agent Skills \ Anthropic
通过渐进式披露管理上下文的工具。最开始agent只加载每个技能的名称和描述,当任务与技能描述匹配时,agent将完整的skill.md解读到上下文中。agent之后根据指令加载文件/工具。
Copilot
https://code.visualstudio.com/blogs/2025/02/24/introducing-copilot-agent-mode
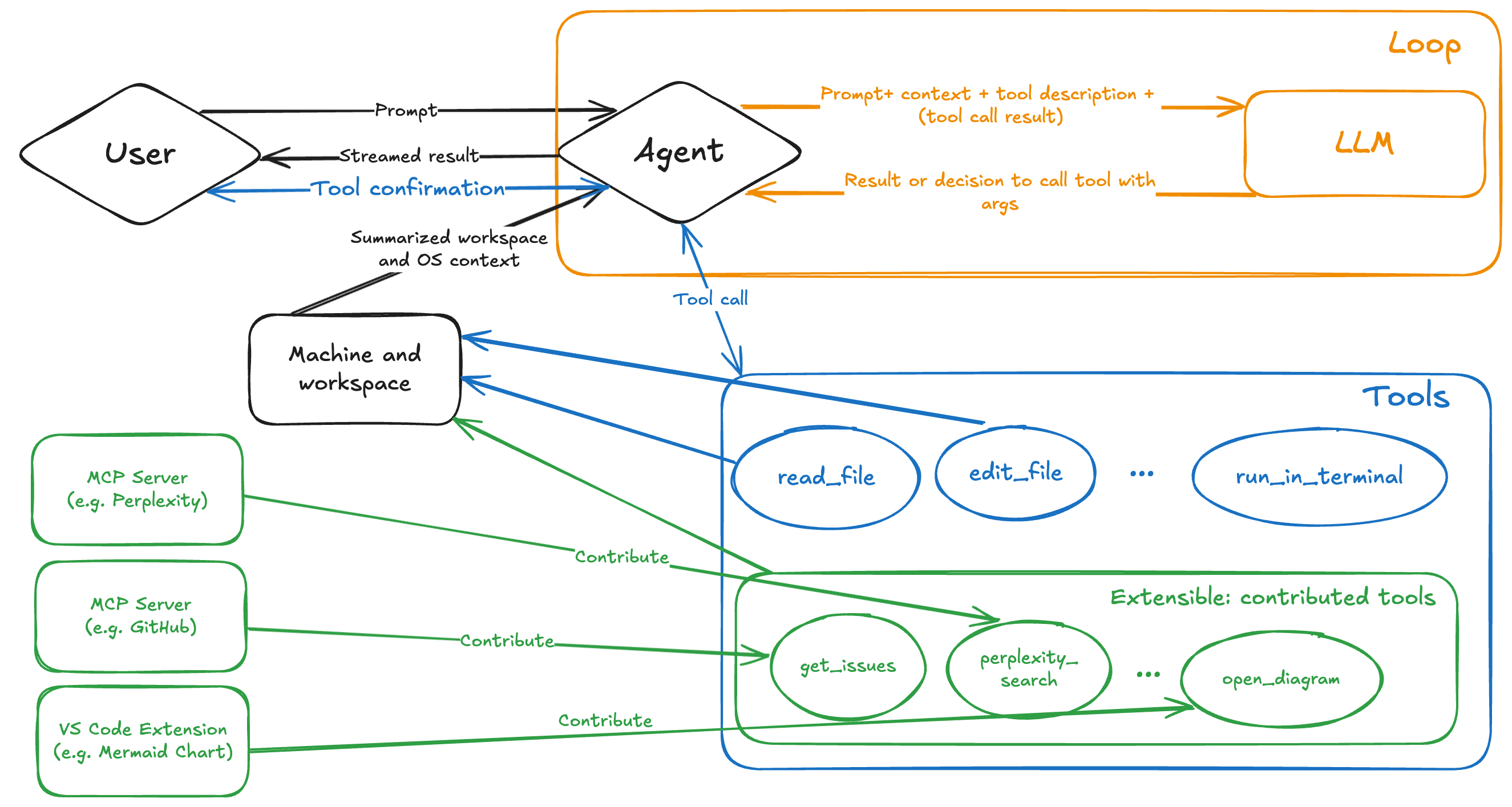 prompt 包括
prompt 包括
- 用户提问
- summarized structure of the workspace
- 一些环境相关的内容
- 工具描述或调用结果
Cursor
Shadow
使用 Shadow 工作区进行迭代 · Cursor 用隐藏窗口和内核级文件夹代理,让AI在不影响用户的情况下在后台迭代代码 需要达到独立性/用户隐私/并发性/通用性/可维护性/速度 希望能够使得AI生成代码的可用性和可运行性 希望实现非阻塞式工作流(ai不会污染用户当前的工作区/打断用户的思路)且向用户交付经过验证的交付物 但是没有实现
instant-apply
以每秒 1000 个��令牌的速度编辑文件 ·光标 传统AI代码生成工具:延迟与非交互性 介绍一个新模型以及其训练和评估方法
- 训练数据
- 80% AI数据,20% 人工数据
- 减小了小文件在训练集的数量
- 减少源于同一个文件名的训练样本数量
- 减少了没有代码更改的数据点
- 评估
- 用ai进行评估
- 测速度 (不同分词器之间标准化,感觉这个就很经典)
- 为何模型选择文件重写而非差异比较
- 难以处理差异编辑
- 差异编辑涉及的tokens太少,模型需要进行前向推导
- 预训练阶段模型接触完整代码多余代码差异文件
- 行号与tokens之间不能一一匹配,模型在计数行号时也表现欠佳(用aider消除行号问题,不用行号,而是用+-)
- 难以处理差异编辑
- 使用了投机编辑技术
Windsurf
feature: DeepWiki/Vibe and Replace/与浏览器&terminal进行互动,抓取浏览器内容和响应/规划模式 windsurf的planning是直接写到markdown里面的,感觉这是比cc好的一点,不过这应该是个user friendly feature 可以自定义一些workflow以及workflow下面特定通用标准的rules,同时可以定义全局rules
另一个feature是可以回滚对话到早期阶段,这个也是十分有趣的
blog
一些比较思维的东西
The Effect of Generative AI on the Human-Tool Interface 生成式ai厉害的一点是高召回,并且进度客观 工具中三种主要的交互类型
- 流程:开发者和工具都知道要做什么并且有能力实行,工具可以加快速度
- 命令:开发者知道结果是什么,但自己无法完成/开销太大,工具通过人类指令回答任务
- 发现:开发者不知道目标结果是什么,处于探索阶段,工具可以通过引导/提示帮助开发者找到正确方向
模型策略
按照产品和用户的需求调节不同的模型
- 模型只是工具的一个部分
- 工具的三部分
- 代码补全 → 延迟至关重要(必须即时)→ 大模型不太可行,从零开始训练模型
- 命令开发 → 接受指令并进行行内重构,提供指令范围内的更改 → 从开源模型进行额外的任务微调
- 聊天 → 延迟有比较大的余地,用户希望答案准确且相关 → 调现有模型的API
- 从产品的角度考虑工具选型
Percentage of Code Written
Percentage of Code Written 简而言之,就是一次PR之中ai编写代码在提交代码之中的占比,作为衡量ai coding 工具的指标,尤其作为一个方向稳定性指标 这个指标的问题:忽略了代码之外的事务在开发中的含金量/忽略了少数核心代码花费的巨量时间/没有对采纳后又被删除的ai代码赋权重/没有进行跨对话测量机制/一些很toy的项目(笑)基本可以全部vibe
有关PCW和CPO
The Golden Metrics: Characters per Opportunity and Percentage Code Written
Characters per Opportunity =
Attempt rate *
Feedback rate *
Acceptance rate *
(Avg Num Tokens / Acceptance) *
(Avg Num Characters / Token)
这个指标在考虑LLM/agent性能的同时还考虑了用户使用LLM的欲望,以及返回信息的长短之类的东西
但并非完美的指标,不包括聊天模式生成的代码,也不包括作者提交对代码的编辑内容
Planning Mode
为SE开发设计的模型SWE-1,背后的思考是:SE需要处理不完整状态并实现长远目标。对于短期操作,SWE-1引入了人类和人工智能共享时间线的表示方法,且人类和人工智能都能感知时间线上的动态。然而,实际上软件开发的过程是一套周密的短期行动方案,所有举措都与长期规划相契合,并且不断受长期规划的完善
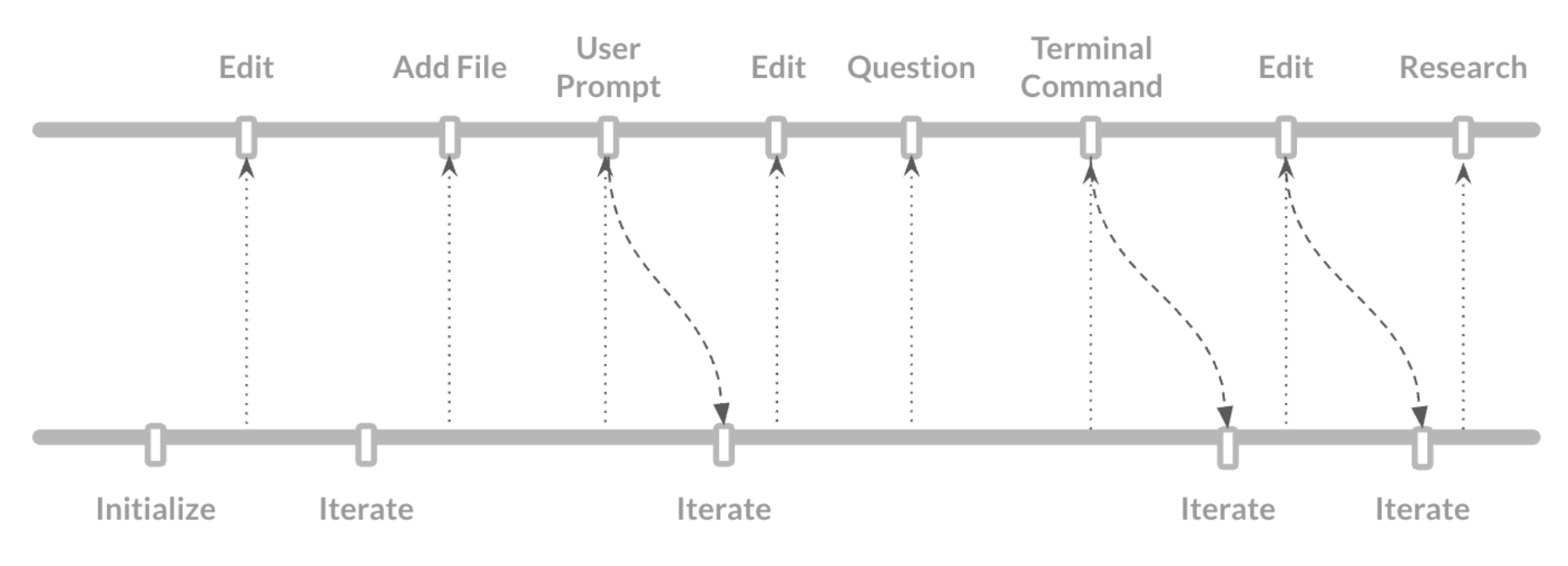
上面的时间线用于短期行动,底部时间线用于长期推演,二者同时发生,要么被潜意识从计划中提取同时计划在持续更新(独立于行动或产生了新信息) 这解释了为啥一部分ai4coding工具在处理复杂任务时会失效,因为它们缺乏计划时间线的基本单元,同时在制定好执行路径之后,缺乏迭代优化计划的意识,因此需要在执行计划的同时修改计划,即让行动时间线上模型得到的东西也影响模型之前做的计划 所以ai模型应当有流程感知的能力,使得ai和人类能够无缝操作,保持流畅,模型可以始终把握用户期待改进的方向 也即构建共享时间线
软件工程本质上是
- 明确构建目标
- 制定构建方案 计划,长期思维 ← 希望人工智能做到
- 执行构建过程 行动,短期思维 ← 人工智能目前在这里
AI长期计划的模式:一个更适合long-term reasoning 的model负责迭代计划,而用户selected的短期模型用于写代��码
而考虑到上面我们讨论的信息,迭代计划的过程应该包括
- 学习新信息的能力(Windsurf: 定制化功能,这些信息来自人类/工具/记忆库)
- 根据新信息更新计划的能力(目前缺失的地方:计划必须以持久化格式保存,且AI和人类都需要具备修改计划的途径)
- Windsurf做的工作:将Markdown文件作为一个接口,人类对Markdown实在是很熟悉,而人工智能也可以通过tools修改
- 确保短期行动始终反映长期计划最新版本(Windsurf:呈现短期行动与长期规划的联合时间线)
更多内容:
- 丰富的呈现形式
- 计划本身也支持多人协作
- 规划时间线超越“初始”和“迭代”,成为流式感知项目管理与架构设计的基础单元
- 计划演进过程被清晰记录,将帮助人工智能获得更soild的数据源
brief ideas about ai agents
Windsurf Launch AI flow:
- context of knowledge → copilot
- access to tools → agent
- real time understanding of human actions → ai flow
重构项目
Dream Bigger
跨多个位置和文件进行推理和编辑
workflow
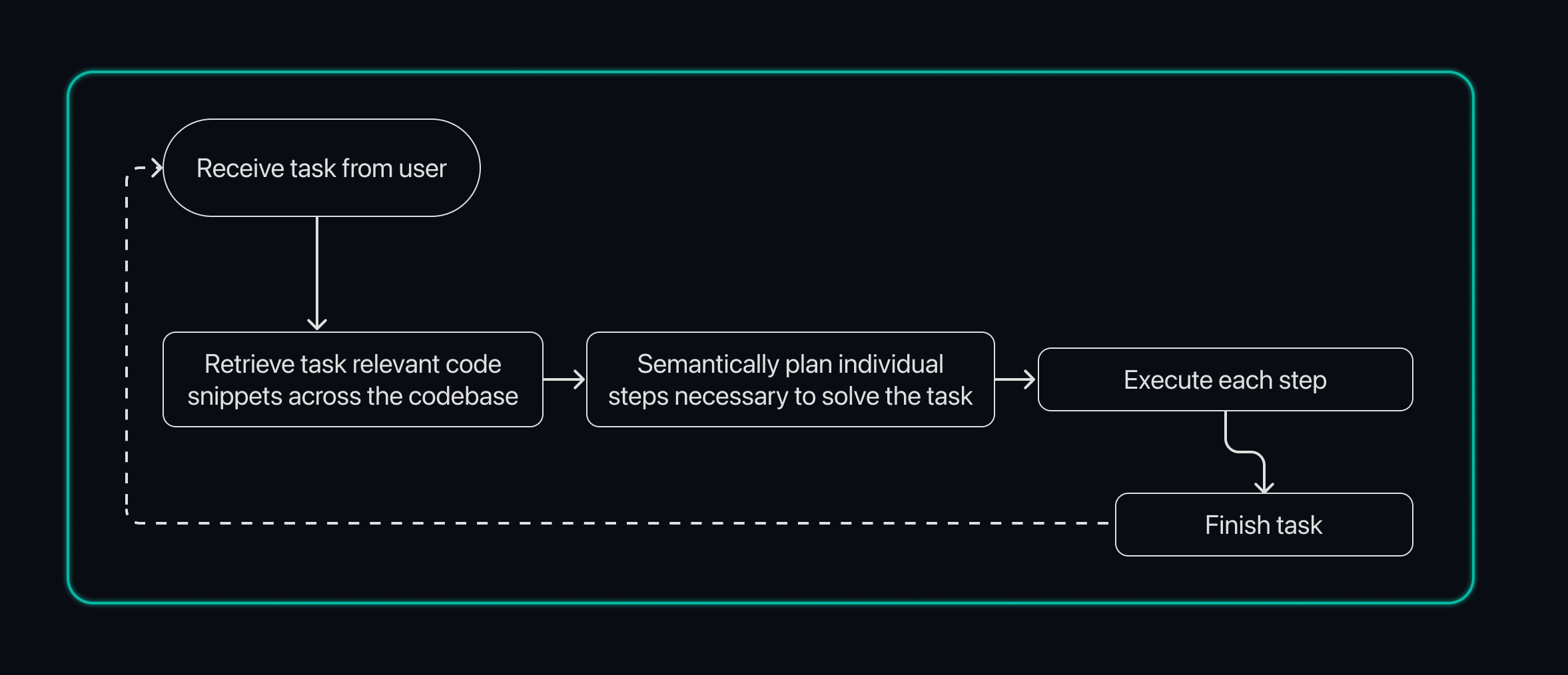
- 对大量数据进行推理
- RAG的问题:随着代码库的变大,嵌入基于向量的检索就会崩溃。Embedding 有固定数量的维度,需要解析的块越多,嵌入向量之间的平均距离就越小,因此在代码库比较大的时候,经常出现误报
- Windsurf训练了一个LLM可以随着可变数量的上下文进行扩展,由底层算力提供支持
- 减少延迟
- 人机交互用户体验
- 快速且容易失败的人工智能也能给人类提供价值
- 只要流程足够快那么开发人员就能给人工智能以反馈
Context
What to Know About the Context Going into your Code LLM
问题:对于编程时开发者需要知道的东西,LLM的上下文十分有限
而即使LLM的上下文得到扩展,一些废话也会污染语料
需要有强大的实时上下文采集和筛选机制,提高进入模型推理的上下文质量
Context Aware Everything: More Advanced Realtime Context than GitHub Copilot
构建了一个系统:ContextModule,可以帮助LLM做context engineering
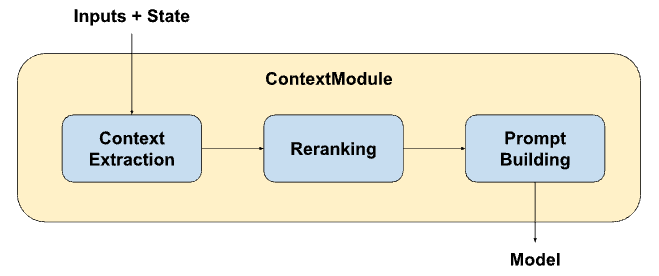 嵌入进行内容提取,排名,之后构建prompt
嵌入进行内容提取,排名,之后构建prompt
除此之外,为什么不使用客户特定微调(CSFT)而是采用上下文感知引擎:因为前者成本高昂,需要定期重复(使得模型与专业知识不断update),导致模型泛化不足和灾难性遗忘(忘记原始预训练中学到的其他编程能力),且受限于模型的大小和延迟
上下文感知:更快速,安全,具有成本效应
之后还有上下文固定功能,让agent在给出答案时更认真地对待其中的代码
代码补全
Why your AI Code Completion tool needs to Fill in the Middle 主要内容是如何训练ai既知道前面的数据又知道后面的数据,简而言之就是倒转一下顺序
代码解析
Using Code Syntax Parsing for Generative AI 不错的想法,但是没有说具体怎么做检索,这不是诈骗吗
延迟
从query给到AI,到AI吐出结果的时间 从产品的角度看,延迟越高越不利 在本地收集上下文,准备进行模型推理 → 上下文传到远程GPU → 实际推理发生 → 推理结果传回 → 将推理结果和现有文本合并 解决延迟:
- GPU编译
- 推理更快的模型架构
- 量化
- 推测解码:选择一个小而且便宜的模型,生成一个“草稿”,然后将这些tokens输入大模型。(对于大模型而言,推理速度�受限于内存带宽,从内存中读大量参数花了比较多的时间,而不是真正的计算,所以处理一个token和处理多个token的时间差不多)大模型批量处理草稿,加速小模型写的对的地方,只在错的地方进行修正。
- 模型并行:在多个GPU上并行推理不同的部分
- 流式处理:提前检测终止条件,并结束延迟
- 上下文缓存:减少生成上下文检索阶段的延迟
- 智能批处理:可以接受相似时间传入的多个请求
评估
为什么你不应该相信你看到的所有数字 大模型评估应当在实际的代码库中进行 codeium的评估方法:
- Use public repositories to find tested functions and corresponding unit tests.
- Automatically delete snippets of said functions
- Simulate autocompleting the deleted snippet
- Re-run the unit tests and see if they still pass
Manus
上下文工程
- 围绕KV缓存进行设计
- 保持前缀稳定(自回归特性,指后面词的生成是前面所有词回归的结果�,导致单个标记的差异会使缓存失效)
- 只增加上下文
- 手动标记缓存断电
- 避免在迭代过程中动态添加/移除工具
- 大多数LLM中,工具定义在序列化后位于上下文的前部,在系统提示前后,这会导致KV缓存失效
- 先前动作观察仍然引用上下文中不定义的工具时,模型会感到困惑。如果没有约束解码,会导致模式违规或者幻觉动作
- manus用状态机管理工具可用性,通过掩码logits(将工具的概率得分降为0)
- 使用文件系统作为上下文
- 通过action读取和写入文件,而非直接把文件塞到上下文之中
- 压缩策略是可恢复的:只保留地址/文档路径,而忽略具体内容
- 通过复述操控注意力
- 将目标复述到上下文的末尾,避免模型忽略长上下文中间的问题
- 图示
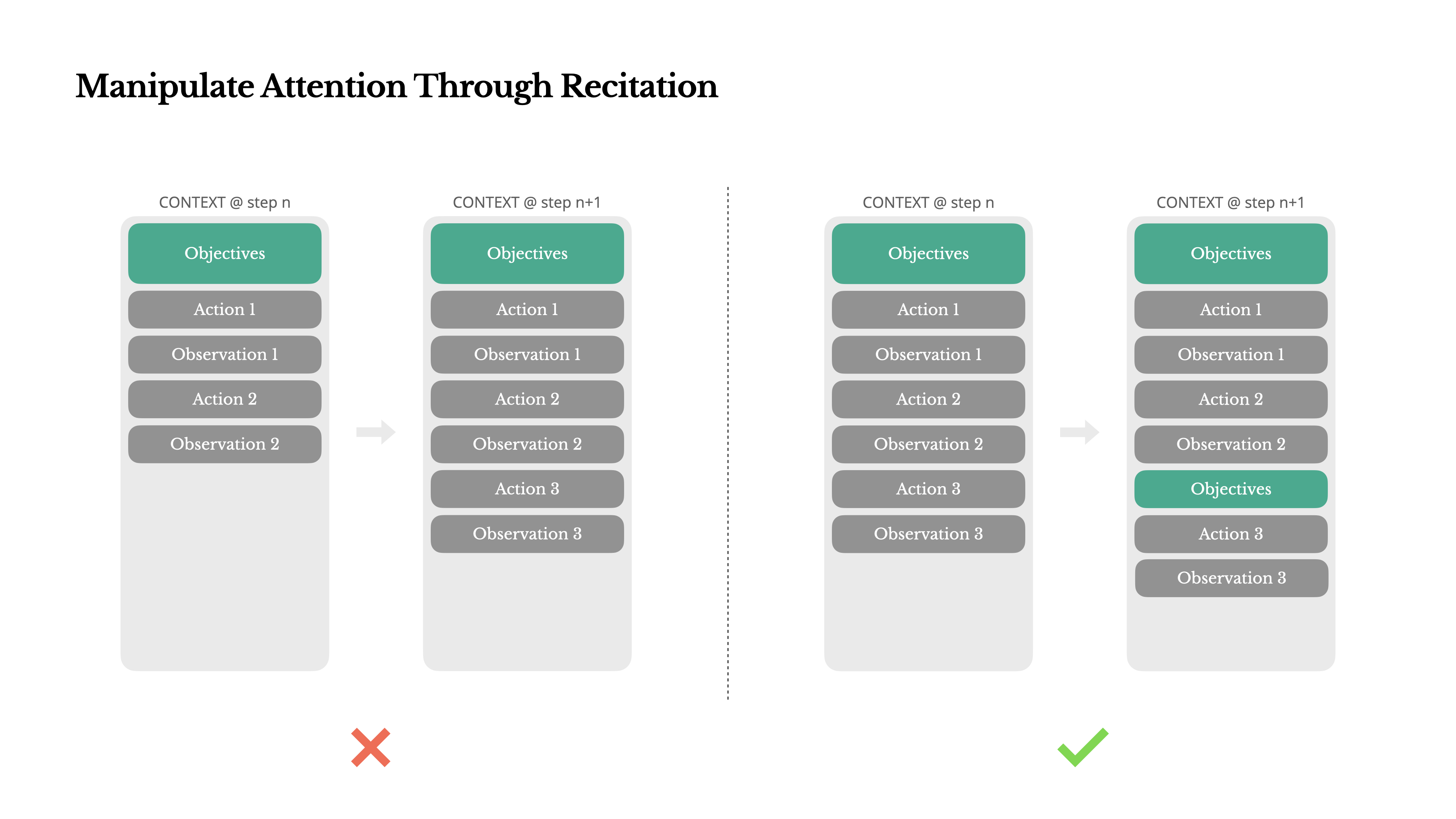
- 保留错误在上下文中
- 模型会隐式更新内部信念,因此将错误的尝试/失败的行动放在上下文中,会降低重复相同错误的可能性
- 我怎么不相信呢.jpg
- LLM倾向于模仿上下文的行为模式,如果上下文中充满了相似的行动-观察对,则大模型会倾向于遵循这个模式
- 需要增加文本的多样性
- 这tm不是左右互搏吗?
wide research
处理ai研究多个实体时的幻觉和编造问题
- 更大的上下文窗口无法解决这个问题
- 衰减不是�二元的
- 处理成本增长(经典transformer的)
- 认知负荷(模型在项目之间不断切换上下文,维护比较框架,并确保风格一致性)
- 上下文长度压力(训练样本中短对话比较多),根本上是架构的限制,因为基于transformer有 的复杂度,同时模型是顺序处理的,上下文越长,要回溯参考的信息越多
- wide research 架构转变:并行处理
- 智能分解
- 委托子��代理(完整的虚拟机环境/独立的工具库/互联网连接/空的上下文窗口)
- 并行执行
- 集中协调,防止上下文污染
- 综合与整合
- 虽然,对此我的评价是,这种方法没办法写特别长且前后交互的文章,比如小说,乐。居然能从理论推导出来吗???
Kiro
Introduce
Introducing Kiro - Kiro 从聊天到规格:深入了解 Kiro 的 AI 辅助开发 - Kiro 了解代码库(生成三个基础文档(同时可以用优化功能优化文档),需要修改功能时,直接在requirement.txt后面加上) → single prompt → requirement → 生成设计文档 → 生成任务和子任务(任务包括单元测试,集成测试,负载状态,移动响应性,可访问性)→ 支持逐个触发任务,进度指示器显示执行状态 规格说明与代码库保持同步 Kiro Hook能捕捉遗漏的问题,类似ts中hook的作用,在文件发生错误时trigger一些东西(可以要求kiro在错误时发现一些东西)
context
停止重复自己:为什么全局转向是您一直缺少的 AI 上下文层 - Kiro krio用全局steering来解决这�个问题,从上到下 企业steering → 个人全局steering → 个人项目steering,后者优先级高于前者